Postado em 4/07/2020
Conteúdo
- Adaboost
- Conjunto de Dados
- Pré-processamento dos registros
- Classificação com Adaboost
- Considerações Finais
Classificador Adaboost
O algoritmo AdaBoost foi desenvolvido em 1996 por Yoav Freund e Robert Schapire. O AdaBoost pode ser utilizado para resolver uma variedade de problemas do mundo real, como classificar os 3 diferentes tipos de flores Iris. O modelo de classificação do AdaBoost atinge seu objetivo final introduzindo sequencialmente novos modelos para compensar as deficiências de outros modelos de classificação.
O AdaBoost é considerado um classificador fraco de repetidas iterações. Em cada chamada, a distribuição dos pesos é atualizada de modo a destacar a importância de cada exemplo no conjunto de dados usado para classificação. Desse modo, após cada iteração os pesos são aumentados quando o exemplo é classificado incorretamente ou diminuído quando classificado corretamente.
Primeiramente, iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifierConjunto de dados
Para esse exemplo, utilizamos o conjunto de dados Iris que possui 150 registros de 3 espécies diferentes de flor Iris: Versicolor, Setosa e Virginica. Cada registro do conjunto possui cinco características: SepalLength (Comprimento da Sépala), SepalWidth (Largura da Sépala), PetalLength (Comprimento da Pétala), PetalWidth (Largura da Pétala) e class (Classe).
Dataset disponível em: https://archive.ics.uci.edu/ml/datasets/Iris
df = pd.read_csv('iris.csv', header=None)
df.columns = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Classes']
df.head()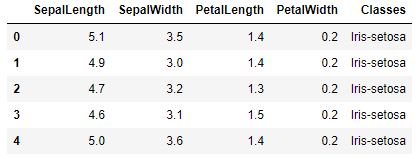
Pré-processamento dos registros
Conforme pode ser visto no carregamento do conjunto de dados, as classes no conjunto de dados são representadas como texto. Iremos transformar as classes para valores numéricos para melhorar o desempenho do classificador.
df["Target"]=0
df['Target']=np.where(df.Classes=="Iris-setosa", 0 ,np.where(df.Classes=="Iris-versicolor",1,np.where(df.Classes=="Iris-virginica",2, "NAN")))
df.head()
df.drop('Classes',axis=1,inplace=True)Agora, determinamos o valor do conjunto de dados de treino em 40% do total de registros. O conjunto de dados é pequeno, com apenas 150 instâncias, o que justifica esse valor. Normalmente, utilizo o Princípio de Pareto, ou também conhecido como Regra 80-20, o qual determina que 80% dos efeitos surgem a partir de apenas 20% das causas, podendo ser aplicado em várias outras relações de causa e efeito.
Porém, no caso deste conjuto de dados, os melhores resultados foram obtidos com 40% dos registros para treinamento. Por que será? Sinceramente, acredito que devido as características de tamanho e largura das pétalas serem muito próximas, aumentar o número registros melhorou os resultados de precisão.
X = df.drop(['Target'], axis=1)
y = df['Target']
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=45)Finalmente, executamos uma pesquisa em grade para ajustar os parametros do classificador. Primeiro, importamos as bibliotecas do Scikit-learn:
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold, train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_scoreEm seguida, determinamos os parâmetros da pesquisa em grade:
dtree = DecisionTreeClassifier()
dtree.fit(x_train,y_train)
clf = GridSearchCV(dtree,
{'criterion': ["gini","entropy"],
'max_depth':[4,5,6,7,8,10],
'min_samples_split':[2,3,4],
'max_leaf_nodes':[3,4,5,6,7,8]})
clf.fit(x_train,y_train)
print(clf.best_score_)
print(clf.best_params_)Com esses valores de ajuste, foi obtido 96,66% de precisão.
Classificação com Adaboost
Para criar o nosso modelo de classificação utilizando Adaboost, iremos primeiramente importar a biblioteca do Scikit-learn:
from sklearn.ensemble import AdaBoostClassifierEm seguida, determinar os seus critérios:
bdt = AdaBoostClassifier(DecisionTreeClassifier(criterion='gini', max_depth=6,
min_samples_split=2,
max_leaf_nodes=5),
algorithm="SAMME",
n_estimators=100,learning_rate=0.2)Utilizaremos o conjunto de testes e treino criados nos passos anteriores:
bdt.fit(x_train,y_train)Ao executar esse último ajuste, teremos a seguinte saída exibindo os critérios que serão utilizados pelo classificador:
AdaBoostClassifier(algorithm='SAMME',
base_estimator=DecisionTreeClassifier(ccp_alpha=0.0,
class_weight=None, criterion='gini', max_depth=6,
max_features=None, max_leaf_nodes=5, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated', random_state=None,
splitter='best'),
learning_rate=0.2, n_estimators=100, random_state=None)
Agora, carregamos o modelo de predição:
y_pred=bdt.predict(x_test)E apresentamos o resultado da precisão, que obteve 96,66%.
accuracy_score(y_test,y_pred)Para uma melhor interpretação, podemos exibir o relatório de classificação do Adaboost:
print("Relatório de Classificação \n",classification_report(y_pred,y_test))Relatório de Classificação
precision recall f1-score support
0 1.00 1.00 1.00 24
1 1.00 0.89 0.94 19
2 0.89 1.00 0.94 17
accuracy 0.97 60
macro avg 0.96 0.96 0.96 60
weighted avg 0.97 0.97 0.97 60
Ou exibir a matriz de confusão:
conf = confusion_matrix(y_test, y_pred)
label = ["Setosa","Versicolor","Virginica"]
sns.heatmap(conf, annot=True, xticklabels=label, yticklabels=label)
plt.show()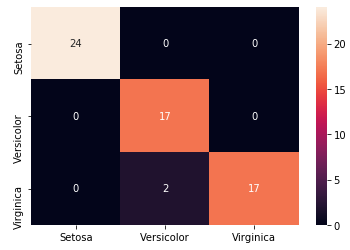
Considerações Finais
Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.