Postado em 8/07/2020
Conteúdo
- Clusterização de Flores Iris Utilizando DBScan
- Conjunto de Dados
- Criando o Modelo de Treinamento
- Considerações Finais
Clusterização de Flores Iris Utilizando DBScan
O algoritmo não supervisionado DBScan (Density-Based Spatial Clustering of Applications with Noise) é destinado a clusterização e um dos mais indicados para identificação de outliers.
As suas principais características são:
- EPS: distância máxima entre 2 amostras para formar um cluster de mesmo tipo (vizinhos).
- minPts: É o número minimo de uma amostra em uma vizinhança para uma amostra ser classificada como “Core Point”
- Core Point: um pouco acima que os minPts na EPS.
- Border Point: um pouco abaixo que os minPts na EPS.
- Noise (Outlier): não é um Core ou Border.
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.cluster import DBSCAN
from matplotlib import pyplot as plt
from sklearn.datasets import make_moons
%matplotlib inlineAlém das bibliotecas Pandas e NumPy, também iremos utilizar o Scikit-learn para utilizar o algoritmo DBSCAN e a biblioteca MatPlotLib para gerar os gráficos.
Conjunto de Dados
Para esse exemplo, utilizei mais uma vez o conjunto de dados Iris. Esse conjunto possui 150 registros de 3 espécies diferentes de flor Iris: Versicolor, Setosa e Virginica. Cada registro do conjunto possui cinco características: SepalLength (Comprimento da Sépala), SepalWidth (Largura da Sépala), PetalLength (Comprimento da Pétala), PetalWidth (Largura da Pétala) e class (Classe).
Dataset disponível em: https://archive.ics.uci.edu/ml/datasets/Iris
df = pd.read_csv('iris.csv', header=None)
df.columns = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Classes']
df.head()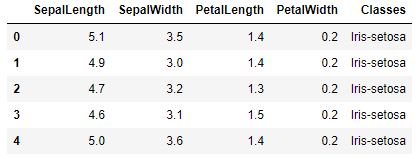
Criando o Modelo de Treinamento
Inicialmente carregamos a base de dados:
model = DBSCAN(eps = 0.8, min_samples=19).fit(df)
print(model)Por que utilizar 0,8 no EPS? Não existe uma regra definicada. Iremos trabalhar com tentativa e erro. A quantidade mínima de amostras em 19 também foi escolhida com base na quantidade de amostras total da base. Esses ajustes são tarefas do Cientista de Dados que deve testar diferentes ajustes em busca do melhor resultado. Mãos a obra!
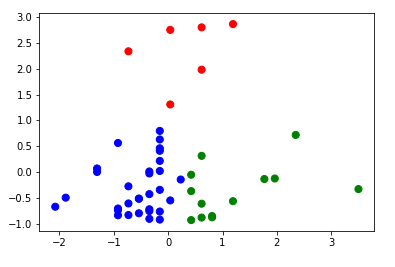
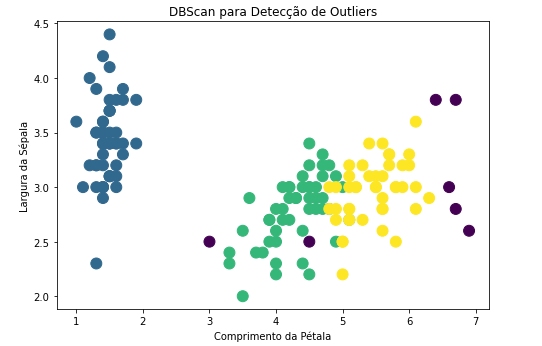
Para facilitar a visualização do modelo criado, iremos selecionar o conjunto de dados que são suspeitas de outliers:
df[model.labels_==-1]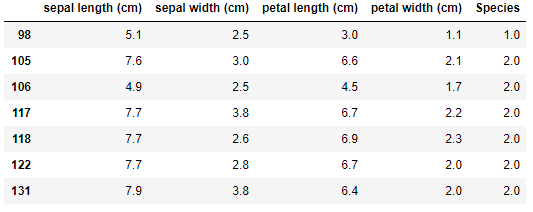
Conseguimos localizar 7 pontos com evidências de serem outliers. O próximo passo é gerar um gráfico:
from sklearn.linear_model import SGDClassifier
sgd =SGDClassifier(penalty='None')
sgd.fit(X_train, y_train)
y_pred =sgd.predict(X_test)
print (classification_report(y_test, y_pred))E o resultado obtido:
Considerações Finais
Nesse tutorial podemos mapear facilmente os outliers. É muito importante conhecer as características dos principais algortimos utilizados pelos Cientistas de Dados. Saber tirar proveitos das suas vantagens irá facilitar no processo de descoberta de conhecimento em diferentes bases de dados.
Esse exemplo com DBScan podem ser aplicado a outras bases disponibilizadas na Internet, bastando fazer alguns ajustes quando necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.