Postado em 9/07/2020
Conteúdo
- Características do Modelo Floresta Aleatória
- Conjunto de Dados
- Criando o Modelo de Treinamento
- Considerações Finais
Características do Modelo Floresta Aleatória
A floresta aleatória é um modelo de aprendizagem supervisionado baseado em árvores de decisão. As árvores de decisão são maneiras extremamente intuitivas de classificar ou rotular objetos: você simplesmente faz uma série de perguntas projetadas para se concentrar na classificação.
No caso da Floresta Aleatória, são montadas vários conjuntos de regras, no qual um novo valor passará por uma série de perguntas, os chamados ramos da árvore, para prever qual é a melhor resposta. Essa é a arquitetura de funcionamento do modelo Floresta Aleatória, no qual os dados são separados aleatoriamente em várias partes e é criada uma árvore para cada uma dessas partes para selecionar a decisão com a resposta mais votada.
A vantagem da Floresta Aleatória é poder ser utilizada para problemas de classificação e regressão. Com poucas exceções, o modelo Floresta Aleatória tem todos os hiperparâmetros de um classificador de uma árvore de decisão e também todos os hiperparâmetros de um classificador de ensacamento, para controlar o conjunto em si. O método de ensacamento consiste em uma combinação de modelos de aprendizagem que aumenta o resultado geral a cada iteração.
Resumindo, a Floresta Aleatória cria várias árvores de decisão e as mescla para obter resultados mais precisos e estáveis.
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
%matplotlib inlineAlém das bibliotecas Pandas e NumPy, também iremos utilizar o Scikit-learn para utilizar método RandomForestClassifier e as biblioteca MatPlotLib e Seaborn para gerar os gráficos.
Conjunto de Dados
Para esse exemplo, foi utilizado o conjunto de dados do naufráfio do navio Titanic, que é usado por muitas pessoas em todo o mundo. Ele fornece informações sobre o destino dos passageiros da embarcação, resumidos de acordo com o status econômico (classe), sexo, idade e sobrevivência. Iremos utilizar o conjunto de dados para prever se um passageiro do Titanic teria sobrevivido ou não.
Dataset disponível em: https://data.world/nrippner/titanic-disaster-dataset
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
ids = test['PassengerId']
print('Train shape : ',train.shape)
print('Test shape : ',test.shape)Conforme a saída gerada no carregamento, o conjunto de treinamento possui 891 registros com 12 atributos e o conjunto de teste possui 418 registros com 11 atributos.
Vamos visualizar o conjunto de dados para verificar seuas principais características:
df = pd.DataFrame(train)
df.head()
O conjunto de treinamento tem 891 registros e 11 características + a variável de destino (Survived). Dois atributos são do tipo floats, cinco inteiros e cinco são objetos. Abaixo apresento uma breve descrição de cada atributo:
- PassengerId: ID único de um passageiro
- Survived: Sobrevivente
- Pclass: Classe de bilhetes
- Name: Nome do passageiro
- Sex: Sexo
- Age: Idade em anos
- Sibsp: Número de irmãos / cônjuges a bordo do Titanic
- Parch: Número de pais / filhos a bordo do Titanic
- Ticket: Numero do bilhete
- Fare: Tarifa de passageiros
- Cabin: Número de cabine
- Embarked: Porto de embarcação
Para uma melhor visualização entre os atributos, vamos visualizar o mapa de calor:
ax = sns.heatmap(train.corr(), cmap=plt.cm.Blues, annot=True)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)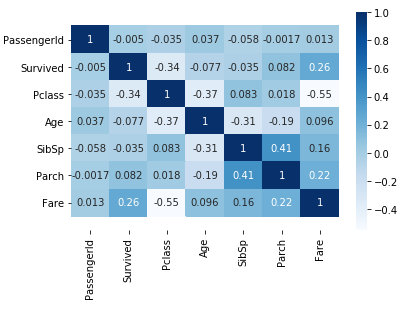
De acordo com o mapa de calor, a maioria dos casos de não sobreviventes está relacionado com a idade, a classe do passageiro e onde foi o embarque. De fato foi esse o ocorrido e iremos treinar o modelo para verificarmos a precisão que podemos obter com Floresta Aleatória.
Criando o Modelo de Treinamento
Inicialmente fazemos alguns ajustes nos atributos do conjunto de treino e eliminar os atributos que considero desnecessário para o treinamento:
le = LabelEncoder()
train['Sex'] = le.fit_transform(train['Sex'].astype(str))
train['Embarked'] = le.fit_transform(train['Embarked'].astype(str))
train.drop(['PassengerId'], axis = 1, inplace = True)
train.drop(['Name'], axis = 1, inplace = True)
train.drop(['Ticket'], axis = 1, inplace = True)
train.drop(['Cabin'], axis = 1, inplace = True)
train.drop(['Age'], axis = 1, inplace = True)
train.head()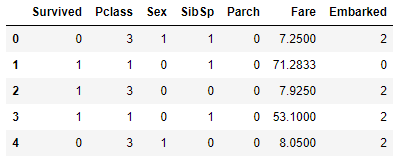
Agora que os dados estão preparados, vamos criar os modelos de treino e teste. Primeiro, dividimos o conjunto de dados em recursos e variáveis de destino:
X=train.iloc[:,1:]
Y=train['Survived'].ravel()Em seguida, dividimos o conjunto de dados em dados de treinamento e teste:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)A seguir, ajustamos os dados de treinamento no classificador:
model = RandomForestClassifier(n_estimators=100).fit(X_train, Y_train)
predict = model.predict(X_test)E finalmente, podemos exibir a precisão do modelo:
print("A acurácia do modelo é :")
print(accuracy_score(predict, Y_test)*100)A acurácia do modelo é :
84.75336322869956
E com o modelo Floresta Aleatória foi obtido 84,75% de precisão.
Considerações Finais
Nesse tutorial utilizamos um dos conjuntos de dados mais trágicos da história. Obtivemos um resultado de 84,75% de precisão com um dos modelos de classificação e regressão mais utilizado pelos Cientistas de Dados. É importante conhecer o seu funcionamento e características para tirar proveitos das suas vantagens e conhecer as suas limitações. Por ser um modelo dericado de Árvores de Decisão, também possuí limitações para lidar com dados com variadas escalabilidades, o que requer muito tempo de pré-processamento dos dados.
Como sempre sugiro, você também pode aplicar esse modelo em outras bases disponibilizadas na Internet, bastando fazer alguns ajustes quando necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.