Postado em 10/07/2020
Conteúdo
- Características do Algoritmo K-Means
- Conjunto de Dados
- Criando o Modelo de Treinamento
- Considerações Finais
Características do Algoritmo K-Means
O algoritmo de clusterização K-Means é capaz de executar a classificação de informações utilizando a análise e a comparação entre valores numéricos dos dados. Essa classificação ocorre de forma automática e sem a necessidade de supervisão humana. Por ser um algoritmo de fácil implementação, mas de custo computacional alto como veremos mais a frente, o K-Means é um dos modelos de aprendizagem de máquina não supervisionado mais utilizados para a mineração de dados.
Para identificar as classes e classificar cada uma das ocorrências, o algoritmo K-Means executa a comparação entre cada valor por meio da distância. Normalmente é utilizada a distância euclidiana, porém outros tipos de medidas podem ser aplicados como a Manhattan, Minkowski, dentre outras. O calculo da distância depende da quantidade de atributos de cada registro fornecido. Quanto mais registros e atributos, maior será o tempo de processamento, aumentando o custo computacional. Isso se deve ao fato que deverá ser calculado as distâncias dos centroides para cada uma das classes. A cada iteração do algortimo K-Means, o valor de cada um dos centroide é refinado pela média dos valores de cada atributo de cada ocorrência que pertence a este centroide. Desse modo, são gerados K centroides para em seguida colocar as ocorrências da conjunto de dados de acordo com sua distância dos centroides.
O algoritmo K-Means é composto de cinco etapas:
- 1ª Etapa: Fornecer valores para os centroides
- 2ª Etapa: Gerar uma matriz de distância entre cada ponto e os centroides
- 3ª Etapa: Colocar cada ponto nas classes de acordo com a sua distância do centroide da classe
- 4ª Etapa: Calcular os novos centroides para cada classe
- 5ª Etapa: Repetir o processo a partir da 2ª etapa para o refinamento do cálculo das coordenadas dos centroides
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import scale
%matplotlib inlineAlém das bibliotecas Pandas e NumPy, também iremos utilizar o Scikit-learn para utilizar o algoritmo K-Means e a biblioteca MatPlotLib para gerar os gráficos.
Conjunto de Dados
Diferentemente dos outros exemplos realizado até o momento, dessa vez optamos por uma abordagem diferente. A lista com os 50 atletas mais bem pagos do mundo foi coletada diretamente do Ranking da Forbes fornecido em seu site. Esse processo de coleta foi realizado utilizando a biblioteca Beautiful Soup. Para que o tutorial não ficassde muito extenso, optei por não colocar as etapas executadas nessa postagem. No futuro eu posso fazer um tutorial de como utilizar a biblioteca Beautiful Soup para coletar dados de sites. Por esse motivo o conjunto de dados em formato CSV está disponível para download no meu GitHub.
Se quiser conhecer o Ranking da Forbes ou coletar mais dados, o site é esse: https://www.forbes.com/athletes/list/#tab:overall.
Obs.: Vale ressaltar que o valor apresentado se refere ao que cada atleta irá receber no ano de 2020. Não se trata da fortuna acumulada por cada um dos atletas ao longo da carreira, uma vez que para isso seria necessário coletar os dados de outras fontes e/ou de anos anteriores da própria Forbes. Mesmo assim, os valores apresentados servem para deixar qualquer mortal admirado com o numerário recebido pelos atletas.
Os atributos que compõe o Ranking coletado são:
- Nome do Atleta
- Salário Total
- Salário recebido por Marketing
- Salário de Atleta
- Esporte do Atleta
- Idade do Atleta
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
df = pd.read_csv('salaries50.csv', delimiter=';')
df.head(10)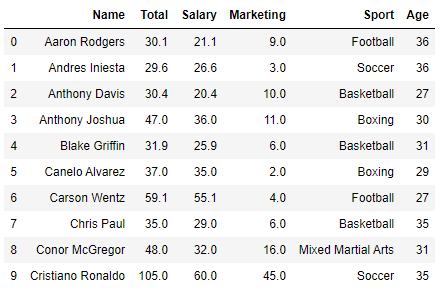
Conforme pode ser visto, a lista está em ordem alfabetica pelo nome do atleta. Vamos ordenar os registros pelo valor total recebido por cada atleta.
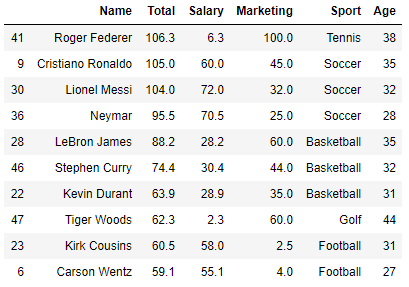
Uau! Não sei definir com o que fiquei mais impressionado. Nesse top 10 muitas coisas chamaram a atenção. O salário recebido em Marketing pelo excelente tenista Roger Federer é mais de 15 vezes o valor do seu salário com premiações e títulos. Pelo que conheço do tenista, ele é um exemplo de atleta e pessoa dentro e fora das quadras. Por passa essa imagem, Federer é patrocinado pelas marcas: Barilla, Credit Suisse Group (ADS), Mercedes-Benz, Rolex, Uniqlo e Wilson Sporting Goods.
Logo em seguida, na segunda posição do Ranking, vem o robozão Cristiano Ronaldo. A sua renda anual ficou ligeiramenmte melhor distruída, mesmo possuindo o terceiro maior salário dentre todos os atletas aqui listado. O maior salário pertence a Lionel Messi e o segundo a Neymar. Aliás, o atleta do Paris Saint Germain é o segundo atleta mais jovem do ranking com 28 anos. Nada mal para o menino Neymar.
Como o nosso objetivo não +e ficar descrevendo os dados coletados, vamos em frente. Primeiramente, iremos verificar os tipos de dados.
df.dtypesE a saída produzida foi:
Name object
Total float64
Salary float64
Marketing float64
Sport object
Age int64
dtype: object
Sensacional! Os principais tipos de dados já estão no formato ideal para serem processados, pois iremos trabalhar a clusterização dos valores em float64 e inteiro: Total, Salary,Marketing e Age.
Com uma simples descrição do dataframe podemos obter mais informações importantes:
df.describe()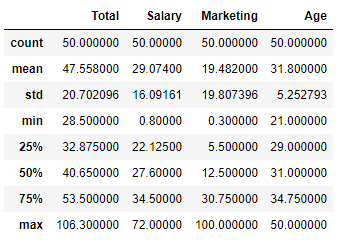
Antes de seguir em frente, apenas para não passarmos em branco com essa Análise Exploratória de Dados (sempre importante para entender melhor o conjunto de dados independente da quantidade de registros), podemos observar que as colunas de salário e idade podem ser consideradas bem distribuídas com os valores de média, minímo e desvio padrão relativamente coerentes. O mesmo não pode ser dito da coluna de Marketing, que apresenta os valores de média e desvio padrão muito próximos, evidenciando que o máximo e mínimo estão muito separados. De fato, o valor máximo de 100 milhões e mínimo de 300 mil indica que esse atleta em particular precisa melhorar a sua imagem ou trocar de empresário. ;)
Vamos plotar alguns gráficos para ter uma melhor compreensão da relação da idade dos atletas com os outros atributos.
f, axs = plt.subplots(1, 3, sharey=True)
f.suptitle('Idade em relação aos outros atributos')
df.plot(kind='scatter', x='Total', y='Age', ax=axs[0], figsize=(15, 3))
df.plot(kind='scatter', x='Salary', y='Age', ax=axs[1])
df.plot(kind='scatter', x='Marketing', y='Age', ax=axs[2])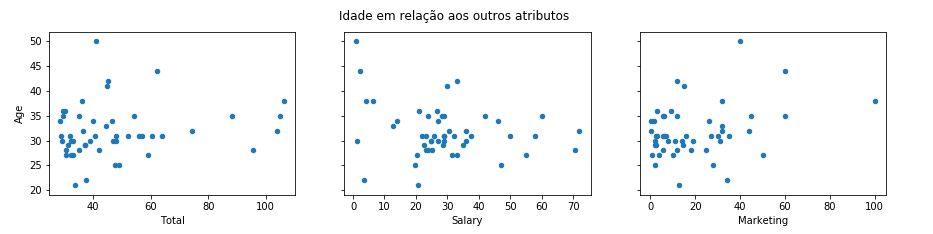
De acordo com os gráficos de dispersão (scatter plots), o grande diferencial são os valores pagos com Marketing. Podemos até ver 3 pontos separados de um grande aglomerado alinahdo a esquerda. Os outros atributos de Salário Total e Salário possuem distribuições razoáveis. Um fato importante que podemos destacar em relação a idade dos atletas é o fato do mais jovem possuir 21 anos e o mais velho 50 anos, sendo a média de idade de 31 anos e 8 meses.
Para entender um pouco mais o conjunto de dados (e finalmente acabar com essa Análise Exploratória de Dados, que aliás eu poderiam ser feitas outras), vamos plotar a relação entre Marketing e Idade:
means = df.groupby('Age').mean()['Marketing']
errors = df.groupby('Age').std()['Marketing'] / np.sqrt(df.groupby('Age').count()['Marketing'])
ax = means.plot.bar(yerr=errors,figsize=(15,5))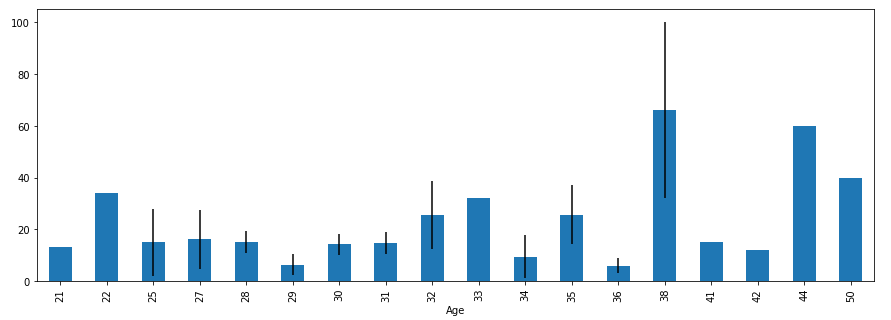
A distribuição dos valores não apresentam nenhuma surpresa, entando os valores de Marketing ligeiramente distribuídos entre as faixas etárias. O destaque fica apeans para a idade de 38 no qual um dos elementos possui uma renda de Marketing mais de duas vezes maior em comparação com o atleta da mesma idade. Analisando o conjunto de dados, verificamos que os atletas em questão são Roger Federer e Serena Williams, ambos tenistas e os maiores vencedores de Grand Slams e títulos em do ATP Tour ainda em atividade. Porém, por motivos que não podemos aferir, possuem essa diferença de valores.
Coincidências a parte, vamos seguir em frente utilizando o algoritmo K-Means.
Criando o Modelo de Treinamento
No algoritmo de clusterização K-means, uma das abordagens mais utilizadas para determinar o valor de K é chamada método cotovelo (The elbow method). Isso envolve executar o algoritmo várias vezes em um loop, com um número crescente de opções de cluster e, em seguida, plotar a pontuação de cluster em relação ao número de clusters.
Uma plotagem típica se parece com a seguinte:
A pontuação é, em geral, uma medida dos dados de entrada na função objetivo de médias k, isto é, a distância intra-cluster em relação à distância interna do cluster.
Para descobrir o valor de K, utilizamos o código a seguir:
k_rng = range(1,10)
sse = []
for k in k_rng:
km = KMeans(n_clusters=k)
km.fit(df[['Age','Marketing']])
sse.append(km.inertia_)
plt.xlabel('K')
plt.ylabel('SSE (Sum Squared Error)')
plt.plot(k_rng, sse)O resultado após a execução do código gerou a imagem a seguir:
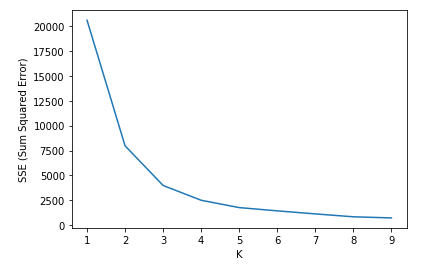
De acordo com a imagem, a curva fica acentuada quando o valor é igual a 3. Iremos utilizar esse parâmetro para treinar o nosso modelo.
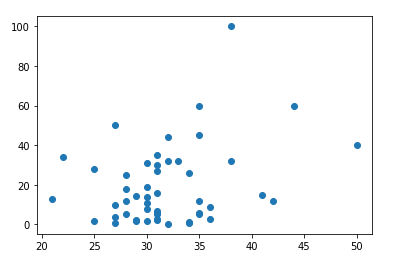
Vamor plotar a relação Idade x Marketing para visualizar os registros antes da clusterização. Para isso basta executar o seguinte código:
plt.scatter(df['Age'], df['Marketing'])Mais fácil impossível! E o resultado apresentado é:
Agora que temos o valor de K, vamos treinar o nosso modelo executando o código a seguir.
km = KMeans(n_clusters=3)
y_predict = km.fit_predict(df[['Age','Marketing']])
df['ypred'] = y_predictEm seguida, vamor gerar um gráfico de dispersão para visualizar os clusters.
cores = np.array(['green', 'red', 'blue'])
plt.scatter(x=df['Age'],
y=df['Marketing'],
c=cores[df.ypred], s=50)E o gráfico gerado com 3 clusters ficou de acordo com o esperado.
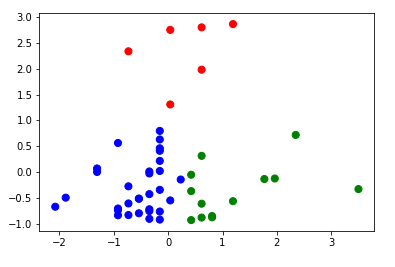
A próxima parte da análise requer um pouco de intuição, uma vez que precisamos interpretar o que os agrupamentos significa. Podemos ver que o segmento representado pelo agrupamento com a cor azul possui registros na faixa etária de 20 a 30 anos e com um rendimento de Marketing de até 60 milhões de doláres no ano de 2020. Na minha opinião esse agrupamento representa os atletas que estão se estabelecendo como grandes estrelas dentro e fora das quadras, podendo vir a ser tornarem grandes garotos(as) propaganda de produtos e marcas, sejam elas ligada ao mundo dos esportes ou não.
o segmento na cor verde possui menos elementos em relação ao grupo anterior e é composto por atletas mais experientes, chegando até a idade máxima aferida nesse conjunto de dados coletado de 50 anos. Os valores anuais recebidos com Marketing também não extrapolam o montante de 60 milhões de doláres no ano de 2020.
Finalmente, o agrupamento vermelho (que deve ser o sonho de todo atleta) possui apenas 6 registros, sendo composto pelos atletas com contratos de Marketing superiores a 60 milhões de doláres no ano de 2020 e, curiosamente, com elementos na faixa etária de 27 a 38 anos.
Considerações Finais
Após toda essa análise, é importante mostrar como a informação adquirida no processo pode ser útil para entender melhor a importancia do Marketing e a relação da idade com a imagem dos atletas. Para complementar esse estudo, aumentar o conjunto de dados poderia apresentar outras informações relevantes que são foram observadas devido a limitação da quantidad de registros. Essa tarefa pode ser realizada num futuro próximo.
Como sempre sugiro, você também pode aplicar esse modelo em outras bases disponibilizadas na Internet, bastando fazer alguns ajustes quando necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.