Postado em 17/07/2020
Conteúdo
- Características do Algoritmo de Regressão Linear
- Conjunto de Dados
- Criando o Modelo de Regressão Linear
- Considerações Finais
Características do Algoritmo de Regressão Linear
O algoritmo de Regressão Linear é utilizado para estimar o valor de algo tendo como base uma serie de outros dados históricos. Esse modelo permite estudar as relações entre duas variáveis numéricas contínuas, que são valores que crescem ou decrescem constantemente. Essas variáveis podem ser definidas como:
- Uma variável de entrada (X) também chamada de variável preditora, explicativa ou independente.
- Uma variável de saída (Y) também chamada de variável dependente resposta ou resultado.
Assumimos que com a Regressão Linear uma variável dependente (Y) é influenciada por uma variável independente (X). As informações sobre a relação entre as variáveis é usada para prever e/ou descrever as mudanças futuras. Desse modo, é possível prever o que acontecerá com Y tendo como base o valor de X.
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn import linear_model
%matplotlib inlineAlém das bibliotecas Pandas e NumPy, também iremos utilizar o Scikit-learn para utilizar o algoritmo de Regressão Linear e a biblioteca MatPlotLib para gerar os gráficos.
Conjunto de Dados
Para esse exemplo, os dados foram coletados do Portal do Instituto Brasileiro de Geografia e Estatistica (IBGE), mais especificamente na seção de Projeções e estimativas da população do Brasil e das Unidades da Federação. Por esse motivo o conjunto de dados em formato CSV está disponível para download no meu GitHub.
Se quiser conhecer mais sobre o Censo Brasileiro ou coletar mais dados, o site é esse: https://www.ibge.gov.br/apps/populacao/projecao/.
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
df = pd.read_csv('censo.csv')
df.head()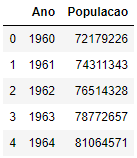
Os dados possuem apenas dois valores, com o Ano e População, no intervalo de 1960 até 2020. Vamos plotar um gráfico com esse conjunto de dados para visualizar melhor.
plt.xlabel('Ano')
plt.ylabel('População')
plt.scatter(df.Ano, df.Populacao, color='green', marker='+')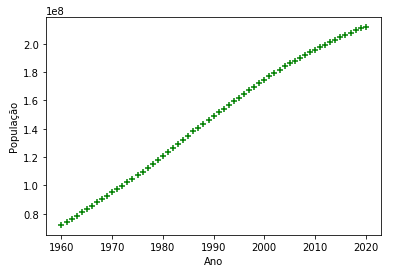
Esse simples modelo mostra o seu potencial de execução, no qual podemos observar que a medida que forem alterados o valor da variável “Ano” o valor da variável “População” também será afetado. Isso mostra que existe um relacionamento linear entre elas.
De posse desta premissa básica, onde esse relacionamento deve existir, partiremos para a construção do nosso modelo de Regressão Linear.
Criando o Modelo de Regressão Linear
Utilizando as variáveis selecionadas, iremos treinar o modelo:
reg = LinearRegression()
reg.fit(df[['Ano']], df.Populacao)
prev = reg.predict([[2021]])
print("Previsão de 2021 é: %d" % prev)E a saída obtida foi:
Previsão de 2021 é: 222679197
E para gerar o gráfico, utilizamos o código a seguir:
plt.xlabel('Ano')
plt.ylabel('População')
plt.scatter(df.Ano, df.Populacao, color='red', marker='+')
plt.plot(df.Ano, reg.predict(df[['Ano']]), color='blue')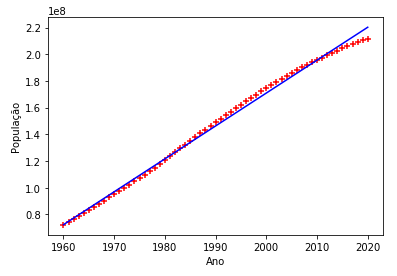
E para efetuar a previsão da expectativa de vida da população, primeiro carregamos o conjunto de dados.
df = pd.read_csv('expectativa.csv')
df.head()E calculamos a previsão.
reg = linear_model.LinearRegression()
reg.fit(df[['Ano']], df.Expectativa)
prev = reg.predict([[2021]])
print("Previsão 2021 é: %d" % prev)E a saída obtida foi:
Previsão 2021 é: 77
E para gerar o gráfico, utilizamos o código a seguir:
plt.xlabel('Ano')
plt.ylabel('Populacao')
plt.scatter(df.Ano, df.Expectativa, color='green', marker='+')
plt.plot(df.Ano, reg.predict(df[['Ano']]), color='blue')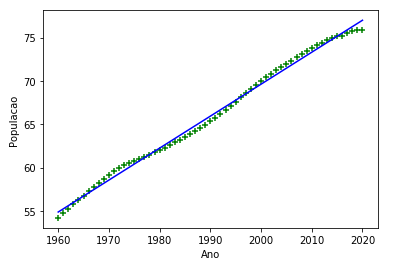
Considerações Finais
É importante ressaltar que correlação não é causalidade. Ou seja, duas variáveis correlacionadas não implicam que uma variável é a causa da outra. Mesmo com uma base de dados confiável, não é possível prever o valor exato da variável de resposta relevante pois podem existir fatores omitidos que podem influenciar a variável de resposta. A regressão linear sempre tem um risco de erro, uma vez que na vida real uma variável independente nunca é uma perfeita preditora da variável dependente.
Como sempre sugiro, você também pode aplicar esse modelo em outras bases disponibilizadas na Internet, bastando fazer alguns ajustes quando necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.