Postado em 18/07/2020
Conteúdo
- Características do Algoritmo de Regressão Logística
- Conjunto de Dados
- Criando o Modelo de Regressão Logística
- Considerações Finais
Características do Algoritmo de Regressão Logística
O algoritmo de Regressão Logística é análogo ao de Regressão Linear, também sendo utilizado para problemas de classificação quando o objetivo é categorizar alguma variável por classes.
Os problemas de classificação podem ser de dois tipos:
- Binários - O cliente quer ou não quer aderir ao seguro
- Multiclasse - Qual candidato eu devo votar?
Vamos começar com o tipo Binário e futuramente veremos o outro.
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from scipy.special import expit
%matplotlib inlineAlém da biblioteca Pandas, também iremos utilizar o Scikit-learn para utilizar o algoritmo de Regressão Logística e a biblioteca MatPlotLib para gerar os gráficos. Finalmente, o método expit da biblioteca SciPy será utilizado para traçar a sigmóide.
Conjunto de Dados
Para esse exemplo, utilizaremos um conjunto de dados em formato CSV está disponível para download no meu GitHub.
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
df = pd.read_csv('seguro.csv')
df.head()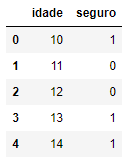
Os dados possuem apenas duas variáveis, sendo uma a idade e a outra se a pessoa possui (valor 1) ou não possui (valor 0) um seguro de vida.
O próximo passo é a construção do nosso modelo de Regressão Logística.
Criando o Modelo de Regressão Logística
Utilizando as variáveis selecionadas, iremos treinar o modelo:
reg = LogisticRegression(solver='lbfgs')
reg.fit(df[['idade']], df.seguro)Agora que foi determinado que a classe idade é o ponto focal para determinar se a pessoa deve ou não aderir ao plano de seguro de vida, vamos realizar algumas previsões. Para isso, basta passar como parâmetro o valor idade para que a função retorne o resultado.
reg.predict([[13], [26], [44], [64], [80]])E a saída obtida foi:
array([0, 0, 1, 1, 1], dtype=int64)
De acordo com o resultado, as pessoas com 13 e 26 anos não aderem ao seguro de vida, enquanto que as com 44, 64 e 80 aderem.
E para gerar o gráfico, utilizamos o código a seguir:
from scipy.optimize import curve_fit
import numpy as np
def f_sigmoide(x, x0, k):
y = 1.0 / (1 + np.exp(-np.dot(k, x-x0)))
return y
popt, pconv = curve_fit(f_sigmoide, df['idade'], df.seguro)
sigm1 = f_sigmoide(df['idade'], *popt)
plt.plot(df['idade'], sigm1)
plt.scatter(df['idade'], df.seguro, c=df.seguro, cmap='Paired', edgecolors='b')
plt.show()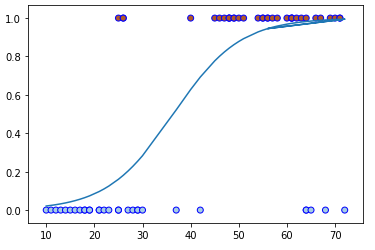
A função chamada sigmóide, também conhecida como função de achatamento, é uma função matemática que tem uma característica de S em forma de curva ou sigmóide curva.
Porém, a função expit já realiza toda essa implementação, e podemos plotar o gráfico da seguinte maneira:
sigm2 = expit(df['idade'] * reg.coef_[0][0] + reg.intercept_[0])
plt.plot(df['idade'], sigm2)
plt.scatter(df['idade'], df.seguro, c=df.seguro, cmap='Paired', edgecolors='b')
plt.show()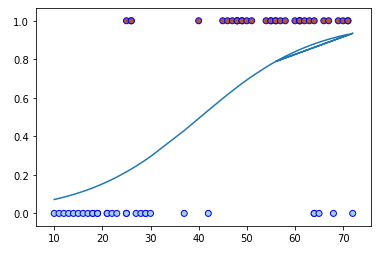
Considerações Finais
A Regressão Logística é um dos métodos de classificação amplamente conhecido e utilizado pelos Cientistas de Dados. Mesmo sendo um método que não apresenta bons resultados de acurácia, é extremamente fácil de ser implementado e pode ser aplicado em problemas onde existem poucas classes. Outro ponto importante é o fato da Regressão Logística fazer parte do bloco fundamental onde são construídas as redes neurais artificias. Desse modo, a sua compreensão é muito importante para a construção de modelos de classificação.
Utilize esse exemplo para criar outros modelos de aprendizagem de máquina utilizando outras bases disponibilizadas na Internet. Para isso, basta efetuasr alguns ajustes quando for necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.