Postado em 20/07/2020
Conteúdo
- Características da Máquina de Suporte Vetorial
- Conjunto de Dados
- Criando o Modelo de Aprendizagem
- Considerações Finais
Características da Máquina de Suporte Vetorial
O algoritmo Support Vector Machine (Máquina de Suporte Vetorial ou SVM) é um modelo de aprendizagem de máquina supervisionado utilizado para a classificação, regressão e também para encontrar outliers. O SVM é capaz de realizar a separação de um conjunto de objetos com diferentes classes utiliza a estratégia de planos de decisão. Para entender como isso é realizado, observe a figura a seguir.
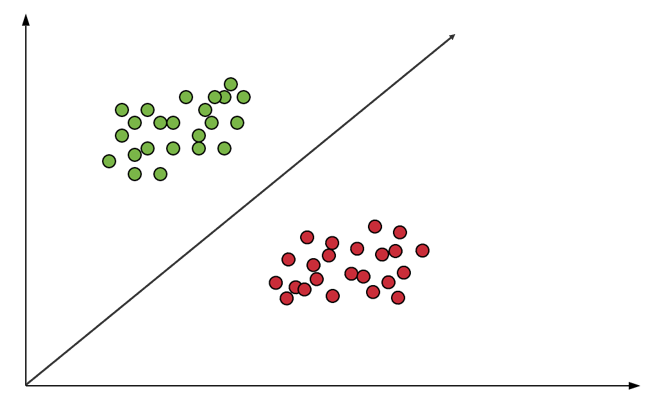
Na figura é possível observar duas classes de objetos: verde ou vermelho. A linha que os separa define o limite em que se encontram os pontos verdes e os pontos vermelhos. Quando um novos objetos forem analisados, estes serão classificados como verdes se estiverem à esquerda e como vermelhos caso situem-se à direita. Nesse exemplo, os objetos foram separados por meio de uma linha (hiperplano) em seu respectivo grupo, caracterizando esse modelo como um classificador linear.
O principal objetivo do SVM é segregar os dados fornecidos da melhor maneira possível. Quando a segregação é feita, a distância entre os pontos mais próximos é conhecida como margem. A abordagem é selecionar um hiperplano com a margem máxima possível entre os vetores de suporte nos conjuntos de dados fornecidos.
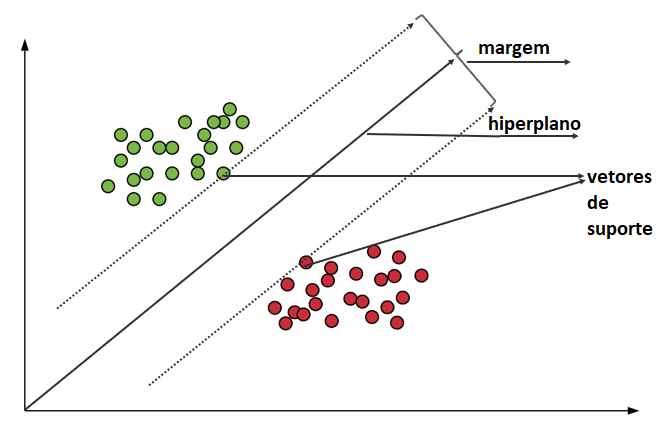
Para selecionar o hiperplano máximo nos conjuntos fornecidos, o SVM segue os seguintes conjuntos:
- Gerando hiperplanos capaz de segregar as classes da melhor maneira possível
- Selecionando o hiperplano correto, que possua a segregação máxima dos pontos de dados mais próximos
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set(font_scale=1.2)
from sklearn import svm
from sklearn import datasets
from sklearn.metrics import confusion_matrix
%matplotlib inlineAlém das bibliotecas Pandas e Numpy, também iremos utilizar o Scikit-learn para utilizar o algoritmo SVM e as bibliotecas MatPlotLib e Seaborn para gerar os gráficos.
Conjunto de Dados
Para esse exemplo, utilizaremos um conjunto de dados em formato CSV está disponível para download no meu GitHub.
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
fruits = pd.read_csv('applesOranges.csv')
fruits.head()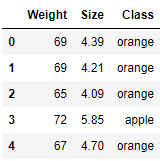
Os dados possuem apenas três variáveis, Peso (Weight), Tamanho (Size) e Classe (laranja ou maça). Vamos plotar uma figura para visualizar os objetos do conjunto de dados.
sns.lmplot('Weight', 'Size', data=fruits, hue='Class',
palette='Set1', fit_reg=False, scatter_kws={"s": 70});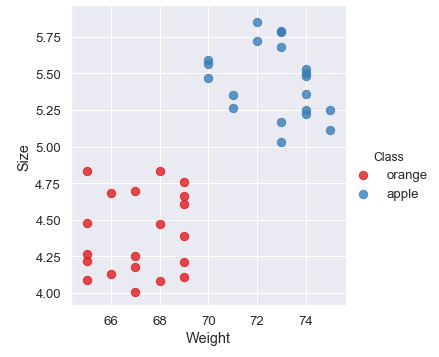
Onde seria o melhor local para inserir uma reta que separaria os dois grupos da melhor forma possível? O próximo passo é a construção do nosso modelo utilizando o algoritmo Support Vector Machine e a criação de um hiperplano capaz de separar as classes do cojunto de dados.
Criando o Modelo de Aprendizagem
Como o SVM é um modelo supervisionado, precisamos indicar os valores que serão utilizados para treinar o modelo. Nesse caso, utilizamos o Peso e Tamanho:
fruta = fruits[['Weight', 'Size']].values
tipo = np.where(fruits['Class']=='orange', 65, 4)Para em seguida treinar o modelo:
model = svm.SVC(kernel='linear', decision_function_shape=None)
model.fit(fruta, tipo)Feito o treinamento, iremos criar dois pontos para definir uma linha (para visualizar) como os objetos estão separados:
w = model.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(60, 80)
yy = a * xx - (model.intercept_[0]) / w[1]E plotamos tudo em um gráfico:
sns.lmplot('Weight', 'Size', data=fruits, hue='Class',
palette='Set2', fit_reg=False, scatter_kws={"s": 70});
plt.plot(xx, yy, linewidth=2, color='black');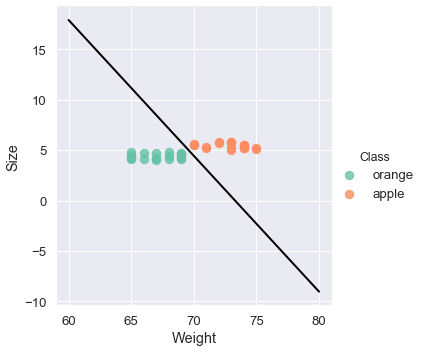
A reta do hiperplano foi encontrada, tendo como base as margens. Vamos inserir as duas linhas das margens para entender o processo.
Primeiro, criamos o modelo:
b = model.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0])
b = model.support_vectors_[-1]
yy_up = a * xx + (b[1] - a * b[0])E geramos um gráfico utilizando o código a seguir:
sns.lmplot('Weight', 'Size', data=fruits, hue='Class', palette='Set2', fit_reg=False, scatter_kws={"s": 70})
plt.plot(xx, yy, linewidth=2, color='black')
plt.plot(xx, yy_down, 'k--')
plt.plot(xx, yy_up, 'k--')
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1],
s=80, facecolors='none');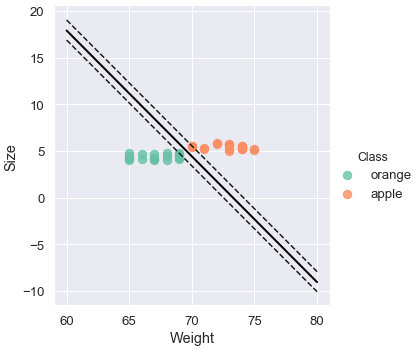
Seguindo as margens, o hiperplano desse Vetor de Suporte foi criado.
De posse desse modelo de previsão podemos criar um pequeno método, de acordo com o código a seguir:
def apple_orange(tam, pes):
if (model.predict([[tam, pes]])) == 0:
print('Isto é uma laranja')
else:
print('Isto é uma maça')Utilizando o método, podemos fazer algumas previsões:
apple_orange(67, 4)E a saída obtida foi:
Isto é uma maça
Parece que está funcionando corretamente. Com isso, criamos um modelo capaz de prever (classificar) laranjas e maças de acordo com o seu Peso e Tamanho.
Considerações Finais
A Máquina de Suporte Vetorial é amplamente utilizado em diversas áreas devido às suas vantagens de aplicação. Dentre suas vantagens destaca-se o bom desempenho de generalização, a tratabilidade matemática, a interpretação geométrica e a utilização para a exploração de dados não rotulados.
Utilize esse exemplo para criar outros modelos de aprendizagem de máquina utilizando outras bases disponibilizadas na Internet. Para isso, basta efetuasr alguns ajustes quando for necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.