Postado em 21/07/2020
Conteúdo
- Características do Algoritmo Vizinhos mais próximos
- Conjunto de Dados
- Criando o Modelo de Aprendizagem
- Considerações Finais
Características do Algoritmo Vizinhos mais próximos
O algoritmo Vizinhos mais próximos (K-Nearest Neighbors ou KNN) é um classificador onde o aprendizado é baseado no quão similar é um dado (um vetor) do outro. O treinamento é formado por vetores de n dimensões.
Para determinar a classe de um elemento que não pertença ao conjunto de treinamento, o classificador KNN procura K elementos do conjunto de treinamento que estejam mais próximos deste elemento desconhecido, ou seja, que tenham a menor distância. Estes K elementos são chamados de K-vizinhos mais próximos. Verifica-se quais são as classes desses K vizinhos e a classe mais freqüente será atribuída à classe do elemento desconhecido.
KNN é um classificador que possui apenas um parâmetro livre (o número de K-vizinhos) que é controlado pelo usuário com o objetivo de obter uma melhor classificação. Este processo de classificação pode ser computacionalmente exaustivo se considerado um conjunto com muitos dados. Para determinadas aplicações, no entanto, o processo é bem aceitável.
O uso do KNN envolve a definição de:
- Uma métrica de distância a ser calculada no espaço dos atributos a fim de determinar os vizinhos mais próximos;
- Um valor para o parâmetro, ou seja, determinar o número de vizinhos que são levados em consideração na geração da saída.
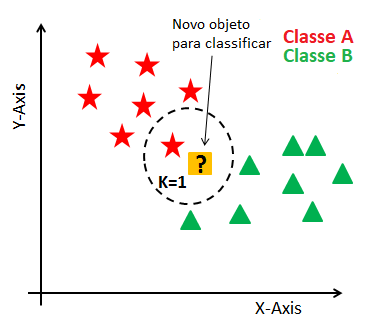
Por conta destas características, o KNN é visto como um método de aprendizado competitivo, uma vez que os elementos do modelo – que são os próprios padrões de treinamento – competem entre si pelo direito de influenciar a saída do sistema quando a medida de similaridade (distância) é calculada para cada novo dado de entrada.
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas nesse exemplo.
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import neighbors
%matplotlib inlineAlém da biblioteca Numpy, também iremos utilizar o Scikit-learn para utilizar o algoritmo KNN e a biblioteca MatPlotLib para gerar os gráficos.
Conjunto de Dados
Para esse exemplo, utilizaremos o conjunto de dados Iris contém quatro atributos (comprimento e largura de sépalas e pétalas) de 50 amostras de três espécies de íris (Iris setosa, Iris virginica e Iris versicolor). Essas medidas foram usadas para criar um modelo discriminante linear para classificar as espécies.
Apenas para referência, aqui estão fotos das três espécies de flores:

Dataset disponível em: https://archive.ics.uci.edu/ml/datasets/Iris
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
iris = datasets.load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)O conjunto de dados Iris foi carregado em uma matriz de dados. A base de dados foi dividida seguindo de acordo com os valores das variáveis explanatórias (tamanho e largura da sépala e tamanho e largura da pétala, que colocaremos em X) e target é a variável resposta contém a definição do tipo de flor (0 para Iris Setosa, 1 para Iris Versicolor e 2 para Iris Virgínica, armazenados em y). Foi utilizado o método train_test_split para retirar 20% dos dados como amostra de teste, tendo então 4 novos valores:
- X_train, armazenará os dados para treino do algorítimo.
- X_test, armazenará os dados para teste.
- y_train, armazenará o resultado para o treino.
- y_test, armazenará o resultado para o teste.
Em seguida, visualizamos o conjunto de dados para verificar a disposicão dos objetos em um gráfico de dispersão:
cores = np.array(['green', 'red', 'blue'])
subplt = plt.scatter(x=X[:, 0], y=X[:, 1], c=cores[y], s=50)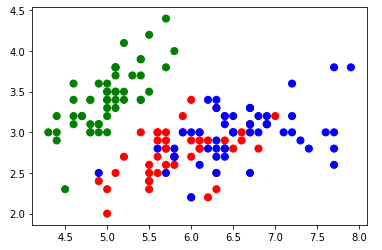
Os objetos na cor verde (Iris Setosa), cor vermelho (Iris Versicolor) e cor azul (Iris Virginica) estão distribuídos no gráfico de dispersão, tendo uma relativa aglomeração dentre as flores do tipo Versicolor e Virgínica. Será que o modelo de aprendizagem KNN terá bons resultados para classificar esses objetos?
Vamos responder essa questão verificando o resultado de preicisão nos próximos passos.
Criando o Modelo de Aprendizagem
De posse dos dados, vamos treinar o modelo de aprendizagem:
clf = neighbors.KNeighborsClassifier()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))E a saída obtida foi:
0.9666666666666667
Ótimo! Foi alcançado uma excelente precisão com 96,67% .
Para estimar um novo objeto, podemos definir uma função ao qual atribuímos as variáveis explanatórias (tamanho e largura da sépala e tamanho e largura da pétala):
estimar = clf.predict([[6.0, 3.3, 4.0, 1.3]])
print(estimar)Nesse exemplo, a saída obtida foi:
[1]
Ou seja, uma flor com esses valores de é do tipo Iris Versicolor.
É possível melhorar essa saída, criando uma estrutura de condição:
predicao = clf.predict([[6.0,3.3,4.0,1.3]])
if predicao == 0:
print(predicao,'- Iris Setosa')
if predicao == 1:
print(predicao,'- Iris Versicolor')
if predicao == 2:
print(predicao,'- Iris Virginica')E a saída obtida foi:
[1] - Iris Versicolor
Parece que está funcionando corretamente. Com isso, criamos um modelo capaz de prever (classificar) os tipos de flores Iris.
Considerações Finais
O KNN explora a ideia de lazy learning, uma vez que o algoritmo não constrói um modelo até o instante em que uma predição é necessária. O KNN tem como desvantagem o fato de que todos os dados de treinamento precisam ser armazenados e consultados para se identificar os vizinhos mais próximos. Mesmo assim, o KNN é um dos mais simples modelos de aprendizagem de máquina para se implementar, tendo uma boa precisão na maioria dos casos aplicados. Além disso, o tempo para se efetuar treinamento dos dados também é diferenciado, sendo um dos mais rápidos para esta atividade.
Utilize esse exemplo para criar outros modelos de aprendizagem de máquina utilizando outras bases disponibilizadas na Internet. Para isso, basta efetuasr alguns ajustes quando for necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.