Postado em 22/07/2020
Conteúdo
- Características do Modelo Estatístico TF-IDF
- Conjunto de Dados
- Análise Exploratória dos Dados
- Pré-processamento Textual
- Vetorização
- Criando o Modelo de Treinamento
- Considerações Finais
Características do Modelo Estatístico TF-IDF
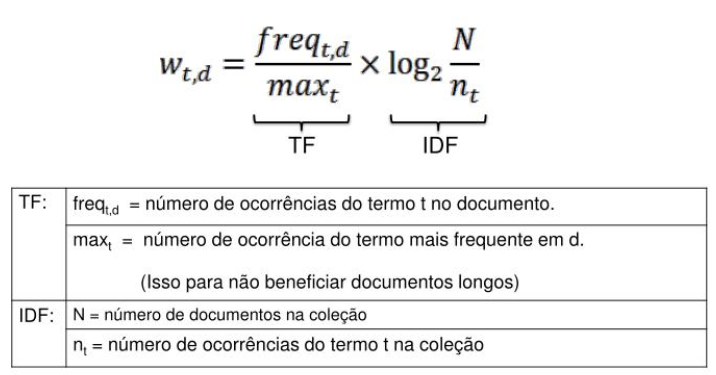
O TF-IDF (Term Frequency – Inverse Document Frequency) é um método estatístico utilizado para medir quais são as palavras mais importantes dentro de um tópico. Para descobrir a relevância dessa palavras em relação ap conjunto total (corpus), o algoritmo analisa a frequência com que essa palavra aparece no documento, comparando o resultado com a quantidade de vezes que ocorre em outro documento.
A frequência do termo (TF) serve para verificar quantas vezes uma palavra aparece em um documento. Ou seja, quanto maior for a frequência no documento, maior será a importância da palavra. Enquanto a frequência inversa dos documentos (IDF) verifica quantas vezes a palavra aparece em todos os documentos da coleção. Desse modo, quanto maior for a frequência nos documentos, menor será a importância da palavra.
O algoritmo utiliza uma razão inversa para calcular a frequência destes termos. Observe o algoritmo:
Para esse exemplo, primeiramente iremos importar as bibliotecas básicas que serão utilizadas.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineAlém da biblioteca Pandas, também iremos utilizar as bibliotecas MatPlotLib e Seaborn para gerar os gráficos.
Conjunto de Dados
Nesse estudo, utilizaremos um conjunto de dados com mais 5 mil mensagens de telefone SMS. Para saber mais sobre as características do conjunto de dados e efetuar o seu download, acesse: https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
Vamos carregar o conjunto de dados para dar início ao nosso exemplo.
sms = [line.rstrip() for line in open('spamData')]
print(len(sms))De acordo com a contagem realizada pela função len, existem exatamente 5.574 mensagens nessa coleção de textos, ao qual pode ser chamada de corpus.
Para ter uma noção desse conjunto, vamos imprimir as 15 primeiras mensagens do corpus e numerá-las utilizando a função enumerate:
for sms_no, sms in enumerate(sms[:15]):
print(sms_no, sms)E a saída produzida foi:
0 ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives around here though
5 spam FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv
6 ham Even my brother is not like to speak with me. They treat me like aids patent.
7 ham As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune
8 spam WINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.
9 spam Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030
10 ham I'm gonna be home soon and i don't want to talk about this stuff anymore tonight, k? I've cried enough today.
11 spam SIX chances to win CASH! From 100 to 20,000 pounds txt> CSH11 and send to 87575. Cost 150p/day, 6days, 16+ TsandCs apply Reply HL 4 info
12 spam URGENT! You have won a 1 week FREE membership in our £100,000 Prize Jackpot! Txt the word: CLAIM to No: 81010 T&C www.dbuk.net LCCLTD POBOX 4403LDNW1A7RW18
13 ham I've been searching for the right words to thank you for this breather. I promise i wont take your help for granted and will fulfil my promise. You have been wonderful and a blessing at all times.
14 ham I HAVE A DATE ON SUNDAY WITH WILL!!
O corpus apresenta um atributo classificando a mensagem como HAM ou SPAM, seguido da mensagem. Esses serão nossos atributos para trabalhamos em nosso modelo.
Em seguida, utilizaremos a função read_csv para tomar nota do argumento sep.
Também iremos aproveitar para renomear as colunas para classe e texto passando uma lista de names.
sms = pd.read_csv('spamData', sep='\t', names=["classe", "texto"])
sms.head()
Análise Exploratória dos Dados
Antes de seguir em frente, vamos verificando algumas das estatísticas utilizando gráficos e outros métodos internos da biblioteca Pandas.
Primeiro, vamos descrever o conjunto de dados.
sms.describe()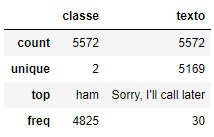
Vamos aplicar a função group by para utilizar a descrição dos rótulos e iniciar a separação das mensagens classificadas como SPAM.
sms.groupby('classe').describe()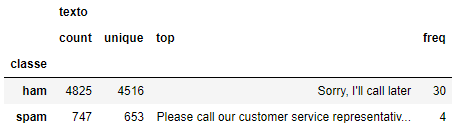
Após agruparmos as classes, podemos verificar que 4.825 são o tipo HAM e 747 do tipo SPAM. É uma boa distribuição, com cerca de 13,41%.
Agora, vamos fazer uma contagem da quantidade de caracteres por mensagem.
sms['tamanho'] = sms['texto'].apply(len)
sms.head()
Vamos visualizar um histograma com o tamanho do texto das mensagens para termos uma melhor compreensão da distribuição do conjunto de dados.
sms['tamanho'].plot(bins=50, kind='hist') 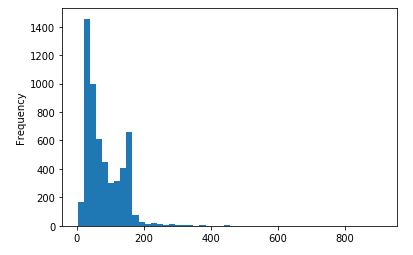
De acordo com o histograma, é possível verificar que existem algumas mensagens longas. O ajuste de bin pode ser um recurso útil para filtrar as mensagens.
Vamos aplicar detalhar um pouco mais o tamnaho das mensagens.
sms.tamanho.describe()E a saída produzida foi:
count 5572.000000
mean 80.489950
std 59.942907
min 2.000000
25% 36.000000
50% 62.000000
75% 122.000000
max 910.000000
Name: tamanho, dtype: float64
De acordo com a descrição, existe uma mensagem com 910 caracteres! Vamos ver do que se trata essa mensagem utilizando o seu tamanho junto com a função iloc.
sms[sms['tamanho'] == 910]['message'].iloc[0]E a saída produzida foi:
"For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don't have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later.."
Shakespeare soube usar as palavras. Já esse Romeu… ;)
Vamos seguir em frente visualizando os histogramas das mensagens classificadas como SPAM ou HAM (não-spam).
sms.hist(column='tamanho', by='classe', bins=50, figsize=(12,4))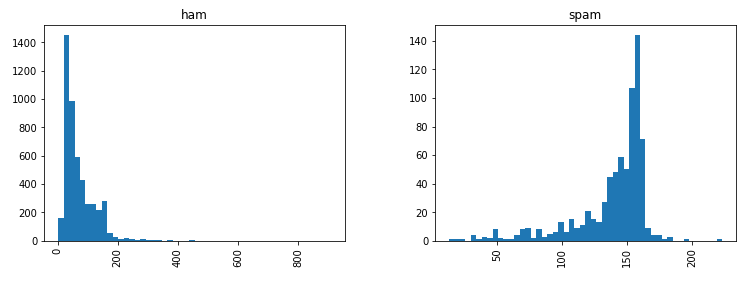
Sensacional! Por isso que a Análise Exploratória dos Dados é importante. Apenas utilizando histogramas e a contagem de caracteres é possível verificar que as mensagens categorizadas como SPAM tem uma ligeira tendência a possuirem mais caracteres.
Agora que terminamos essa análise, vamos aplicar um pouco de processamento textual em nosso conjunto de dados.
Pré-processamento Textual
Iremos efetuar etapas de pré-processamento para converter as mensagens brutas (sequência de caracteres) em vetores (sequências de números).
Vamos iniciar removendo a pontuação das mensagens. Para isso, iremos utilizar a biblioteca string do Python e obter uma lista rápida de todas as pontuações possíveis.
import string
mess = 'For God so loved the world that he gave his one and only Son, that whoever believes in him shall not perish but have eternal life.'
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)Em seguida, vamos imprimir a mensagem sem a pontuação.
nopunc.split()E a saída produzida foi:
['For',
'God',
'so',
'loved',
'the',
'world',
'that',
'he',
'gave',
'his',
'one',
'and',
'only',
'Son',
'that',
'whoever',
'believes',
'in',
'him',
'shall',
'not',
'perish',
'but',
'have',
'eternal',
'life']
Agora, iremos remover as palavras muito comuns, conhecidas como stopwords (‘the’, ‘a’, etc.), utilizando a biblioteca NLTK.
clean_mess = [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
clean_messE a saída produzida foi:
['God',
'loved',
'world',
'gave',
'one',
'Son',
'whoever',
'believes',
'shall',
'perish',
'eternal',
'life']
Ótimo! Palavras como “For”, “so”, “the”, dentre outras, foram removidas. Agora vamos criar um função que contenha essas duas etapas. Em seguida, iremos aplicá-la em nosso DataFrame com as mensagens SMS.
def text_process(mess):
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)
return [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]E vamos aplicar essa função em nosso conjunto de mensagens.
sms['texto'].head(5).apply(text_process)E a saída após o pré-processamento foi:
0 [Go, jurong, point, crazy, Available, bugis, n...
1 [Ok, lar, Joking, wif, u, oni]
2 [Free, entry, 2, wkly, comp, win, FA, Cup, fin...
3 [U, dun, say, early, hor, U, c, already, say]
4 [Nah, dont, think, goes, usf, lives, around, t...
Name: texto, dtype: object
Comparando com a imagem a seguir, podemos ver que o pré-processamento está funcionando corretamente.
A seguir, vamos transformar as mensagens em vetores para poder utilizar o modelo estatístico TF-IDF do Scikit-learn.
Vetorização
A vetorização será realizada em 3 etapas, utilizando o modelo bag-of-words:
- Contando a quantidade de vezes que uma palavra ocorre em cada mensagem (frequência do termo)
- Verificando o peso das contagens, para que os tokens frequentes tenham um peso menor (frequência inversa do documento)
- Normalizando os vetores para o comprimento da unidade, para abstrair o comprimento do texto original (norma L2)
Cada vetor terá tantas dimensões quanto houver palavras exclusivas no corpus de mensagens SMS. Primeiro, usaremos a função CountVectorizer das biblioteca Scikit-learn. Este modelo converterá uma coleção de documentos de texto em uma matriz de contagens de tokens.
Podemos imaginar isso como uma matriz bidimensional, onde a 1ª dimensão é o vocabulário inteiro (1 linha por palavra) e a 2ª dimensão são os documentos reais, nesse caso, uma coluna por mensagem de texto.
Como existem muitas mensagens, podemos esperar muitas contagens zero para a presença de palavras nesses documentos. Por isso, o Scikit-learn produzirá uma matriz esparsa.
A função CountVectorizer possui muitos argumentos e parâmetros que podem ser passados. Em nosso exemplo, iremos especificar somente o método analyzer definido anteriormente. A execução dessa função demorará um pouco devido ao tamanho do corpus.
from sklearn.feature_extraction.text import CountVectorizer
bow_transformer = CountVectorizer(analyzer=text_process).fit(sms['texto'])
print(len(bow_transformer.vocabulary_))E a saída após a vetorização:
11425
E temos mais de 11.400 palavras!
Vamos escolher aleatoriamente uma mensagem e executar uma contagem utilizando bag-of-words como vetor, colocando em uso a função bow_transfrmer.
sms4 = sms['texto'][113]
print(sms4)I'm ok wif it cos i like 2 try new things. But i scared u dun like mah. Cos u said not too loud.
E agora vamos criar a representação vetorial dessa mensagem.
bow4 = bow_transformer.transform([sms4])
print(bow4)
print(bow4.shape) (0, 423) 1
(0, 1523) 1
(0, 2352) 1
(0, 5727) 1
(0, 6204) 1
(0, 7800) 2
(0, 7908) 1
(0, 7990) 1
(0, 8413) 1
(0, 8567) 1
(0, 9512) 1
(0, 9565) 1
(0, 10432) 1
(0, 10655) 1
(0, 10698) 2
(0, 11072) 1
(1, 11425)
De acordo com a saída, existem 14 palavras exclusivas na mensagem número 114 (após remover stopwords). Duas palavras ocorrem duas vezes. Vamos confirmar quais palavbras ocorrem duas vezes.
print(bow_transformer.get_feature_names()[7800])
print(bow_transformer.get_feature_names()[10698])like
u
Tudo funcionando corretamente. Agora podemos utilizar a função .transform no conjunto de bag-of-words (bow) e transformar todo o DataFrame de mensagens.
Vamos verificar no conjunto de bag-of-words se o corpus SMS é uma matriz esparsa. A execução dessa função demorará um pouco devido ao tamanho do corpus.
sms_bow = bow_transformer.transform(sms['texto'])
print('Tamanho da Matriz esparsa: ', sms_bow.shape)
print('Quantidade de ocorrências diferentes de zero: ', sms_bow.nnz)Tamanho da Matriz esparsa: (5572, 11425)
Quantidade de ocorrências diferentes de zero: 50548
Agora, vamos calcular a esparsidade.
sparsity = (100.0 * sms_bow.nnz / (sms_bow.shape[0] * sms_bow.shape[1]))
print('sparsity: {}'.format(round(sparsity)))sparsity: 0
Zero! É justamente para isso que serve o modelo estatístico TF-IDF. Tendem a se aproximar de zero, todos os termos que se repetem em todos os documentos ou aqueles que aparecem em apenas um documento.
Vamos aplicar mais uma transformação em nosso exemplo com a mensagem 114.
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer().fit(sms_bow)
tfidf4 = tfidf_transformer.transform(bow4)
print(tfidf4) (0, 11072) 0.2544685557864205
(0, 10698) 0.2621619510877923
(0, 10655) 0.23254617444910455
(0, 10432) 0.23254617444910455
(0, 9565) 0.32927152337716614
(0, 9512) 0.21266843775055871
(0, 8567) 0.19436100053650282
(0, 8413) 0.20574396725319594
(0, 7990) 0.28536759996146216
(0, 7908) 0.32927152337716614
(0, 7800) 0.33861647601039374
(0, 6204) 0.23254617444910455
(0, 5727) 0.22526004471154445
(0, 2352) 0.1576749522332345
(0, 1523) 0.2630036332107152
(0, 423) 0.145737456490222
Agora, vamos verificar qual é a IDF (frequência inversa de documentos) das palavras like e u.
print(tfidf_transformer.idf_[bow_transformer.vocabulary_['like']])
print(tfidf_transformer.idf_[bow_transformer.vocabulary_['u']])4.236617057753035
3.2800524267409408
Aparecem poucas vezes, dado o tamanho do conjunto de palavras.
Agora, vamos transformar todo o conjunto de palavras em um conjunto de TF-IDF de uma só vez.
sms_tfidf = tfidf_transformer.transform(sms_bow)
print(sms_tfidf.shape)(5572, 11425)
Existem muitas maneiras de efetuar pré-processamento textual e vetorizar palavras. As etapas envolvem planejamento de recursos e a construção de um processo de execução. A documentação do Scikit-learn pode ajudar a lidar com dados textuais. Além disso, existem muitos artigos e livros disponíveis sobre o tópico geral de Processamento de Linguagem Natural (PLN).
Criando o Modelo de Treinamento
Com as mensagens representadas como vetores, podemos finalmente treinar nosso classificador de SPAM. Praticamente podemos utilizar qualquer tipo de algoritmo de classificação. Nesse exemplo, iremos utilizar o classificador Naïve Bayes.
from sklearn.naive_bayes import MultinomialNB
spam_detect_model = MultinomialNB().fit(sms_tfidf, sms['classe'])Vamos classificar uma única mensagem e verificar o resultado.
print('Predito:', spam_detect_model.predict(tfidf4)[0])
print('Esperado:', sms.classe[3])Predito: ham
Esperado: ham
Perfeito! Desenvolvemos um modelo que pode prever a classificação de SPAM.
Agora, iremos determinar o desempenho geral do modelo em todo o conjunto de dados.
Vamos começar obtendo todas as previsões.
all_predictions = spam_detect_model.predict(sms_tfidf)
print(all_predictions)['ham' 'ham' 'spam' ... 'ham' 'ham' 'ham']
Podemos utilizar o relatório de classificação interno do Scikit-learn, que retorna precisão, cobertura, acurácia, F1-Score e uma coluna de suporte (ou seja, quantos casos suportaram essa classificação).
from sklearn.metrics import classification_report
print (classification_report(sms['classe'], all_predictions)) precision recall f1-score support
ham 0.98 1.00 0.99 4825
spam 1.00 0.85 0.92 747
accuracy 0.98 5572
macro avg 0.99 0.92 0.95 5572
weighted avg 0.98 0.98 0.98 5572
Nada mal! Nosso modelo está com 98% de precisão.
Agora vamos testar o modelo. O tamanho do teste é 20% de todo o conjunto de dados (1115 mensagens do total de 5572) e o treinamento é o restante (4457 de 5572).
from sklearn.model_selection import train_test_split
msg_train, msg_test, label_train, label_test = \
train_test_split(sms['texto'], sms['classe'], test_size=0.2)
print(len(msg_train), len(msg_test), len(msg_train) + len(msg_test))4457 1115 5572
Vamos executar nosso modelo novamente e depois prever o teste. Usaremos os recursos pipeline do Scikit-learn para armazenar um pipeline de fluxo de trabalho. Isso permitirá configurar todas as transformações que faremos nos dados para uso futuro.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('bow', CountVectorizer(analyzer=text_process)),
('tfidf', TfidfTransformer()),
('classifier', MultinomialNB())
])Agora podemos transmitir diretamente os dados do texto da mensagem e o pipeline fará o pré-processamento. A execução dessa função demorará um pouco devido ao tamanho do corpus.
pipeline.fit(msg_train,label_train)Pipeline(memory=None,
steps=[('bow',
CountVectorizer(analyzer=<function text_process at 0x00000260E2F7E288>,
binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8',
input='content', lowercase=True, max_df=1.0,
max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None,
stop_words=None, strip_accents=None,
token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)),
('tfidf',
TfidfTransformer(norm='l2', smooth_idf=True,
sublinear_tf=False, use_idf=True)),
('classifier',
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True))],
verbose=False)
E aplicar a predição em nosso conjunto de teste. A execução dessa função demorará um pouco devido ao tamanho do corpus.
predictions = pipeline.predict(msg_test)
print(classification_report(predictions,label_test)) precision recall f1-score support
ham 1.00 0.95 0.98 1003
spam 0.71 1.00 0.83 112
accuracy 0.96 1115
macro avg 0.85 0.98 0.90 1115
weighted avg 0.97 0.96 0.96 1115
E obtemos 96% de precisão com esse modelo.
Agora, vamos criar uma matriz de confusão utilizando a biblioteca Seaborn e exibir o relatório de classificação do conjunto de testes.
import seaborn as sns
import numpy as np
from sklearn.metrics import precision_recall_fscore_support
import matplotlib.pyplot as plt
y = np.random.randint(low=0, high=5, size=5)
y_p = np.random.randint(low=0, high=5, size=5)
def plot_classification_report(y_tru, y_prd, figsize=(4, 3), ax=None):
mask = np.zeros((3, 4))
mask[:,3] = True
plt.figure(figsize=figsize)
xticks = ['precision', 'recall', 'f1-score'
# , 'support'
]
yticks = list(np.unique(y_tru))
yticks += ['avg']
rep = np.array(precision_recall_fscore_support(y_tru, y_prd)).T
avg = np.mean(rep, axis=0)
avg[-1] = np.sum(rep[:, -1])
rep = np.insert(rep, rep.shape[0], avg, axis=0)
ax = sns.heatmap(rep,
mask=mask,
annot=True,
cbar=False,
xticklabels=xticks,
yticklabels=yticks,
ax=ax,
annot_kws={"size": 15, "color":"blue"})
plot_classification_report(predictions,label_test)E o gráfico gerado ficou de acordo com o esperado.
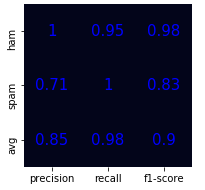
A próxima parte da análise requer um pouco de intuição, uma vez que precisamos interpretar a matriz de confusão. Os resultados para a classificação de mensagens do tipo HAM, ou seja, mensagens consideradas válidas está excelente, com 100% de precisão, 95% de recall e f1-score com 98%. Já no caso do SPAM a taxa de precisão é de 71%. Por que isso acontece? Bom, de certo modo se deve pela quantidade de mensagens da classe SPAM. Como vimos na Análise Exploratória dos Dados, correspondem a 13% do total. Por essa razão, a precisão pode ter tido essa classificação baixa com o nosso modelo. Por outro lado, o recall ficou com 100%, o que é execelente, ou seja, obteve a revocabilidade máxima (sem falsos negativos).
Considerações Finais
Apresentamos mais um modelo de aprendizagem de máquina amplamente utilizado pelos Cientistas de Dados. Como sempre, vale a pena ressaltar as vantagens desse método, das quais destaco a sua facilidade de implementação e de calcular a frequência de termos mais descritivos em um documento, além de ser muito utilizado para calcular a similaridade entre dois documentos. Por outro lado, dentre as desvantagens, o modelo estatístico TF-IDF utiliza o conceito de bag-of-words, que não captura a posição no texto, a semântica, as co-ocorrências em diferentes documentos, e outras características de escrita que determinam a importância de uma palavra dentro de um texto. Por esse motivo, o TF-IDF é útil apenas como um recurso de nível lexical. Portanto, depende muito do que você deseja usar o TF-IDF.
Como sempre sugiro, você também pode aplicar esse modelo em outras bases disponibilizadas na Internet, bastando fazer alguns ajustes quando necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.