Postado em 27/07/2020
Conteúdo
- Pré-processamento de Dados e suas Características
- Dividindo os conjuntos de dados de Treinamento e Teste
- Tratando dos valores ausentes
- Tratando dos recursos categóricos
- Normalização de dados
- Considerações Finais
Pré-processamento de Dados e suas Características
O pré-processamento de dados é uma das etapas essenciais para o bom desempenho dos modelos de aprendizagem de máquina. Trata-se de uma das habilidades que todo Cientista de Dados deve aprender antes mesmo de dominar os algoritmos mais utilizados. Por esse motivo, iremos apresentar aqui algumas dicas para aprimorar suas técnicas e garantir que seus dados alcancem o melhor resultado possível.
De acordo com muitos cientistas dados, a aprendizagem de máquina pode ser divida em 80% para o pré-processamento de dados e 20% para a construção dos modelos. Talvez você já tenha ouvido algo parecido em outras áreas que processam dados para a extração de conhecimento. O fato é que os dados que passam pelas corretas etapas de pré-processamento são capazes de produzir resultados visivelmente melhores em comparação com os modelos no qual os dados não foram bem pré-processados.
Além disso, o pré-processamento de dados é necessário porque os dados do mundo real são geralmente incompletos (faltando valores de atributo, faltando certos atributos de importância ou possuem apenas dados agregados), ruídosos (contém erros ou outliers) e inconsistentes (possuem discrepâncias em códigos ou nomes).
As etapas de pré-processamento dos dados mais comuns são:
- Limpeza de dados - Processo utilizado para preencher valores ausentes, suavizar os dados ruidosos, identificar ou remover os valores discrepantes e resolver as inconsistências. Essa etapa é necessária porque os sistemas de origem contêm dados sujos (ruídosos) que devem ser limpos. As atividades de limpeza de dados são:
- Parsing: localizar os dados de elementos individuais em arquivos de origem para, em seguida, isolar esses elementos no arquivo de destino. Por exemplo, localizar um indivíduo pelo seu nome ou sobrenome e armazená-lo em uma estrutura apropriada.
- Correção: corrigir ou enriquecer os dados individuais identificados no processo de parsing utilizando algoritmos sofisticados ou fontes de dados secundárias. Por exemplo, adicionar o CEP ausente de um endereço.
- Padronização: aplicar rotinas de conversão para transformar dados em um formato específico. Por exemplo, converter temperaturas de Fahrenheit para Celsius, dado que existem sistemas que possuem dados nesses dois formatos.
- Correspondência: pesquisar e fazer a correspondência de registros dentro e por meio do parsing, correção e padronização com base em regras de negócios predefinidas para eliminar redundância (dados duplicados). Por exemplo, a identificação de nomes e endereços semelhantes.
- Consolidação: analisar e identificar relacionamentos entre registros correspondentes e os consolidar/mesclar em uma representação. Por exemplo, identificar os dependentes de um funcionário utilizando o seu nome ou CPF.
- Enriquecimento: incluir dados ausentes ou corrigir dados incorretos de uma nova fonte para lidar com os muitos tipos de erros possíveis.
- Armazenamento temporário: acumular dados de fontes assíncronas. Pode ocorrer em um horário de corte predefinido, no qual os dados do arquivo temporário são transformados e carregados em outro repositório. Geralmente, o usuário final não tem acesso ao arquivo temporário.
- Integração de dados - Processo para combinar os dados de várias fontes em um armazenamento de dados coerente, como por exemplo um armazém de dados (data warehouse). As fontes podem incluir vários bancos de dados, cubos ou arquivos de dados. As atividades de integração de dados são:
- Integração de esquemas: integrar os metadados de diferentes fontes. Por exemplo, integrar do dados de entidades do mundo real de várias fontes de dados utilizando o CPF.
- Detecção e resolução de valores conflitantes: padronizar os valores que representam a mesma entidade do mundo real quando vindos de fontes diferentes. Por exemplo, todos os valores devem ser convertidos na mesma escala (metros, centímetros, Celsius, etc.).
- Eliminação de redundância: evitar que ocorra a redundância de registros, uma vez que o mesmo atributo pode ter nomes diferentes em fontes diferentes.
-
Transformação de dados - Processo para lidar com a correção de qualquer inconsistência, caso exista. Um dos problemas mais comuns é a inconsistência na nomeação de atributos. Isso ocorre principalmente porque o mesmo atributo pode ser referido por nomes diferentes em várias fontes de dados. Por exemplo, o atributo nome pode ser NAME em uma fonte e NM_PESSOA em outra.
- Redução de dados - Processo para obter uma representação reduzida em um volume de dados, mas que produz os mesmos resultados analíticos ou similares. Esse tipo de pré-processamento é essencialmente necessário para:
- Reduzir o número de atributos
- Reduzir o número de valores do atributo
- Reduzir o número de instâncias (tuplas)
-
Discretização de dados - Processo para reduziz o número de valores de um determinado atributo contínuo, dividindo o intervalo do atributo contínuo em intervalos. Os rótulos de intervalo podem ser utilizados para substituir os valores reais dos dados.
- Sumarização de dados - Processo para reduziz os dados coletando e substituí-los por conceitos de baixo nível. Por exemplo, sumarizar valores numéricos para o atributo idade por conceitos de nível superior (como jovens, adulto, meia-idade ou sênior).
Nesse tutorial, iremos mostrar quatro tipos de pré-processamento de dados utilizando Python com as bibliotecas Pandas, Numpy e Scikit-learn:
- Dividindo os conjuntos de dados de Treinamento e Validação
- Tratando dos valores ausentes
- Tratando dos recursos categóricos
- Normalização de dados
Dividindo os conjuntos de dados de Treinamento e Teste
Essa é claramente uma das etapas mais importantes da Aprendizagem de Máquina. Ela é muito importante porque o modelo construído precisa ser avaliado antes de ser implantado. Como a avaliação do modelo precisa ser realizada utilizando dados não vistos (utilizados), nada melhor do que dividir o conjunto de dados em duas partes, separando uma delas com dados que não foram utilizados durante a fase de treinamento.
Além disso, os dois subconjuntos criados deve possuir dados de treinamento e suas etiquetas de treinamento e dados de teste e suas etiquetas de teste. Um das maneiras mais fácil de fazer isso é usando o Scikit-learn, que possui uma função denominada train_test_split.
O código para realizar essa divisão é apresentado a seguir.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)Aqui passamos X e y como argumentos em train_test_split, que divide X e y de modo que haja 20% de dados de teste e 80% de dados de treinamento divididos com êxito entre X_train, X_test, y_train e y_test. Essa proporção utiliza o Princípio de Pareto, ou também conhecido como Regra 80-20, no qual determina que 80% dos efeitos surgem a partir de apenas 20% das causas, podendo ser aplicado em várias outras relações de causa e efeito.
Tratando dos valores ausentes
Os valores ausentes (também chamado de lixo) devem ser removidos ou tratados nos conjuntos de dados. Se o conjunto de dados estiver cheio de NaNs e valores considerados como lixo, certamente o modelo também executará esse lixo. Portanto, antes de criar o modelo de Aprendizagem de Máquina é importante tratar esses valores ausentes.
Para esse tutorial, iremos utilizar um conjunto de dados fictícios para ver como podemos tratar os valores ausentes. O dados pode ser obtidos aqui.
Primeiro, vamos verificar os valores ausentes no conjunto de dados.
import pandas as pd
import numpy as np
import sklearn
df = pd.read_csv('preprocessing.csv')
df.isna().sum()
Como por ser visto, existem dois valores ausentes em quatra colunas. Uma abordagem que pode ser aplicada para preencher os valores ausentes é preenchê-lo com a média da coluna. Por exemplo, podemos preencher o valor ausente da coluna final por uma média de todos os alunos da coluna.
Para fazer isso, podemos usar a função SimpleImputer em sklearn.impute.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(fill_value=np.nan, strategy='mean')
X = imputer.fit_transform(df)Isso preencherá todos os valores ausentes utilizando a média da coluna. Usamos a função fit_transform para fazer isso.
Como a função retorna uma matriz Numpy, para lê-la, podemos convertê-la novamente no DataFrame.
X = pd.DataFrame(X, columns=df.columns)
print(X)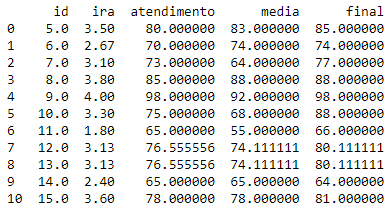
Como pode ser verificado, os valores ausentes foram preenchidos com a respectiva média de cada coluna. A função SimpleImputer também pode ser utilizada para preeencher outras medidas de centralidade, como moda, mediana, máximo, etc.
Se o número de linhas com valores ausentes for pequeno ou se os dados estiverem dispostos em uma ordem que não seja aconselhável preencher os valores ausentes, uma outra estatégia pode ser eliminar as linhas ausentes utilizando a função dropna do Pandas.
dropedDf = df.dropna()Desse modo, foram descartadas todas as linhas nulas do conjunto de dados e as armazenamos em outro DataFrame.
dropedDf.isna().sum()Agora temos zero linhas nulas ou com valores faltantes.
Tratando dos recursos categóricos
Podemos tratar dos recursos categóricos convertendo-os em números inteiros.
Utilizando LabelEncoder, podemos converter os valores categóricos em rótulos numéricos. Para esse exemplo, utilizaremos esse conjunto de dados:
paises = pd.read_csv('preprocessingPaises.csv')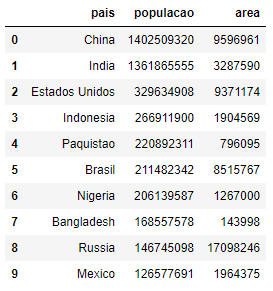
Utilizando o codificador de etiquetas na coluna país iremos converter a China em 2, a Índia em 4, os EUA em 3 e assim por diante. Vamos codificar.
from sklearn.preprocessing import LabelEncoder
l1 = LabelEncoder()
l1.fit(paises['pais'])
paises.pais = l1.transform(paises.pais)
print(paises)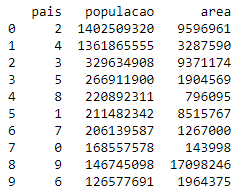
Essa técnica tem uma desvantagem: por ordenar as etiquetas alfabeticamente, dará prioridade a Rússia devido ao rótulo ser alto (9) e a Bangladesh a menor prioridade pelo rótulo ser baixo (0), mas ainda assim, ajudará muitas vezes.
Normalização de dados
A normalização de dados é uma das técnicas mais utlizadas em Aprendizagem de Máquina. Foi provado, por meio de experimentos, que os modelos de Aprendizagem de Máquina têm um desempenho muito melhor em um conjunto de dados normalizado em comparação ao mesmo conjunto de dados que não foi normalizado. O desempenho pode ser tanto em tempo de execução (custo computacional) e até mesmo o resultado de precisão.
O objetivo da normalização é alterar valores para uma escala comum sem distorcer a diferença entre o intervalo de valores.
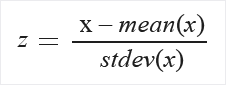
De acordo com a documentação oficial do Scikit-learn, a normalização é o “processo de dimensionar amostras individuais para obter uma norma de unidade. Esse processo pode ser útil se for utilizar em seu modelo uma forma quadrática, como produto escalar ou qualquer outro núcleo, para quantificar a semelhança de qualquer par de amostras”.
O processo para normalizar utilizando o Scikit-learn é muito simples e nesse exemplo iremos criar dois códigos.
from sklearn.preprocessing import minmax_scale
from sklearn.preprocessing import scale
paises = pd.read_csv('preprocessingPaises.csv')Primeiro, iremos obter os nomes das colunas do DataFrame como uma lista.
cols = list(paises.columns)Em seguida, remover a coluna país que não será normaliza.
cols.remove('pais')Agora, podemos copiar os dados e aplicar a normalização por reescala nas colunas do DataFrame que contém valores contínuos. Por padrão, o método minmax_scale reescala com min=0 e max=1.
paises_amp = paises.copy()
paises_amp[cols] = paises[cols].apply(minmax_scale)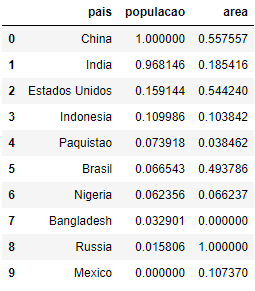
Finalmente, podemos copiar os dados e aplicar a normalização por padronização a todas as colunas do DataFrame. Por padrão, o método scale subtrai a média e divide pelo desvio-padrão.
paises_dist = paises.copy()
paises_dist[cols] = paises[cols].apply(scale)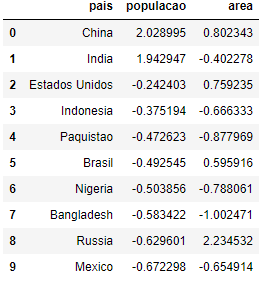
Existem várias outras maneiras de normalizar os dados, sendo todas úteis em casos específicos. Você pode ler mais sobre eles na documentação oficial aqui.
Considerações Finais
Conforme apresentado, todas essas técnicas melhorarão suas habilidades gerais como Cientista de Dados e o resultado dos modelos de aprendizado de máquina. Utilize esse exemplo para criar outros modelos de aprendizagem de máquina utilizando outras bases disponibilizadas na Internet. Para isso, basta efetuasr alguns ajustes quando for necessário. Todo o código e mais um pouco está disponível no meu GitHub.
Os passos de execução deste tutorial foram testados com Python 3.6 e tudo ocorreu sem problemas. No entanto, é possível que alguém encontre alguma dificuldade ou erro no meio do caminho. Se for o caso, por favor comente a sua dificuldade ou erro neste post.